Improving Rails scalability using modularity with enforced boundaries
I did a talk at LRUG (London Ruby User Group) on this! If you like this post, or prefer video based content, you can check it out here.
Ruby & Rails have a reputation for not scaling well — you’ve probably heard this already.
TLDR for this post
There’s 3 things I’m going to talk about that have been used to improve the scalability of a Rails application.
1. Make the Rails application modular
2. Create a clear dependency graph
3. Enforce the boundaries between those separate modules
Contents
Make the Rails application modular
— Why does it end up like this?
— How should we split the application into modules?
— What have people tried in order to achieve modularity in a monolithic Rails application?
Create a clear dependency graph
Enforce the boundaries between those separate modules
— What do I mean by enforcing boundaries?
— Why doesn’t Rails enforce boundaries?
— Options for enforcing boundaries (tests and Packwerk)
Make the Rails application modular
Modular programming is a software design technique that emphasizes separating the functionality of a program into independent, interchangeable modules, such that each contains everything necessary to execute only one aspect of the desired functionality.
Many rails applications eventually become an entangled mess of code where a developer can’t easily reason:
1) How the code is organised (the different sections and how they relate to each-other) and what it’s doing
2) What might break when you change one section of the application (what parts of the codebase depend on what other parts of the codebase)
Why does it end up like this?
- The default Rails folder structure encourages you to organize your code in layers rather than modules.
This is the default structure of a Rails application.

This doesn’t tell you much about what the application does — just that it’s implemented in models, views and controllers (the layers). And even then, there’s no guarantee that the boundaries between these sections of the code are enforced.
2. Ruby/Rails doesn’t encourage you to modularise your code in the same way some languages do
If you look at Java (from Java 9) you have ‘modules’ which group ‘packages’ (which are groups of Java classes that relate to each other) and enforce the boundaries between those modules. This is a clear and explicit aspect of the language.
This means that looking at a Java application that uses modules, you could easily see what modules exist (which gives you a pretty good view of how the application code is structured, and what the application does) and what the dependencies between those modules are (so that you’d be confident on what might break if you change a particular module).
We don’t have anything as explicit in Ruby/Rails. People have discovered ways to kind of achieve this (see the ‘what have people tried’ section below) but it feels more like workarounds than a deliberate aspect of the language/framework.
How should we split the application into modules?
This is what I’ll talk about least in this post, but it’s obviously something you’ll need to think a lot about. DDD seems to be a popular approach to decide the bounded contexts within your application and split the code into modules that represent those bounded contexts, I’d recommend this post to see an example within the modular monolith context and this has been touted as the go to book on DDD.
Doing one ‘big bang’ PR to completely re architect an application is one way (this was Shopify’s approach with their humongous Rails application) but breaking out single components over time, or introducing new functionality as components is also a common approach — I like the questions Gousto asked themselves before deciding whether a new feature was a separate enough domain to build outside their normal Rails structure.
What have people tried in order to achieve modularity in a monolithic Rails application?
This isn’t exhaustive (if you know other attempts please comment and I’ll update) but here are some ways people have attempted to modularise a Rails monolith:
- Rails engines.
Rails engines seem to be a very popular approach for achieving modularity and have well documented successes. The idea is that for each component in your application you create a Rails engine, which is like its own stand alone Rails application with its own models, views and controllers. For example Devise is a Rails engine that you include and use in your own application — check out its repo and notice that it has its own app/ folder with views and controllers!
Aside from the clear separation another massive benefit is that if you load the engines using Bundler you are prevented from having circular dependencies (read the Circular Dependencies section of Modular Monolith). This means that you’ll have a clear dependency graph that can only flow one way, and that’s massive.
Component Based Rails Applications (Cbra) is a popular architecture and you can start your research here if you haven’t heard of it or listen to this talk. Another popular use of Rails engines for this goal is the Modular Monolith which breaks down a real life example of how Root used Rails engines and components to achieve modularity. Airtasker have also broken down their approach to modularization using Rails engines which is well worth a read. Gousto have a great blog on how they used a Rails engine for a new feature that they considered breaking into its own external service but wrote as an engine inside the monolith instead. Lastly, shopify have broken their enormous Rails application into components and heavily utilise Rails engines (although not for everything) — they’ve got many blog posts but here’s one, and another to get you started.
2. Extracting components to the lib directory or a new directory at the root level of the application
This approach is similar to the above in terms of intent, the intention is to group the domain logic of an application into clearly defined components and then namespace those components outside of the standard app folder but without using Rails engines.
By not using Rails engines our components won’t have their own views and controllers, this means that the approach outlined by Dan in the Modular Monolith where he breaks the API and Admin (admin dashboard) into separate components wouldn’t be possible as you’d need Admin to have it’s own views etc. However, you’re not always going to need views and controllers for components — at Simply Business we had a Rails application that was responsible for attributing sales to partners with a lot of domain logic that we’d gone through a long DDD process to clearly define and represent in our code. We architected the code in a similar fashion to Ubers domain-orientated microservices architecture (where we used folders with enforced boundaries— see packwerk below — instead of microservices).
The downside of this approach is that now you have the app folder doing its normal Rails thing but also now these separate components. If it’s impossible to mistake that logic should go in the component and not the app folder (which was the case for us at Simply Business because almost all the logic was in the components folder) or everyone is aware that logic relating to certain functionality should go in these components then you’re golden, but if people start creeping functionality into app/ then beware you may end up with code spread across the app.
3. Extracting gems
Rails engines are distributed as gems, but it’s also possible to just create standard gems that encapsulate domain logic. For example if you are building an application for an insurance company, you could encapsulate all the logic relating to rating (which will take all the information about a customer and create insurance quotes for them) into a gem.
This approach has similarities to the above 2 — it’s got similar benefits to rails engines (e.g. it creates a very clear place for logic that is within your application but clearly separate, and bundler prevents circular dependencies so if you had multiple gems then you’d only ever have a dependency graph that has arrows pointing in one direction between them) but the gems only encapsulate domain logic, they will work alongside the normal Rails application to utilise views and controllers.
Create a clear dependency graph
A dependency graph is a directed graph that represents the dependencies of several objects towards each other…the main question you need to answer is: if I touch this, what else would be impacted? Source
You can use automated tools like rubrowser to automatically generate this for you.
Ideally your graph would look something like this:
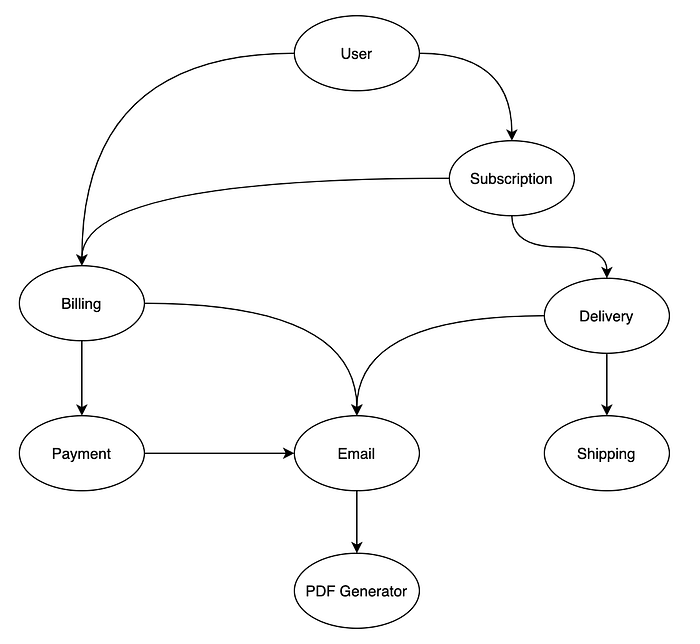
Notice that the arrows only go one way. For example, Subscription points to (i.e. depends on) Billing and Delivery. This means that if we changed either Billing or Delivery then there’s a chance that Subscription has broke BUT if we change Subscription then we shouldn’t need to run the tests for Delivery or Billing. The rule is that when we change the system from the diagram above, we only need to check the component we change or the components that have arrows pointing into it.
There are so many benefits to this but here are my 2 favourite:
1. It’s easy to reason about how your system interacts at a high level. If someone new joined tomorrow you could show them this dependency graph and they’d have a pretty good understanding of what the app is doing and how it’s organised by this graph alone.
2. When you make changes in a component, you feel confident that you’re not breaking unexpected parts of your system. Note this only applies if you have enforced boundaries (i.e. you feel confident because you 100% know that nowhere uses this class/module apart from this defined list).
See Steve Hagemann explain this and even more benefits.
You might find that your Rails application looks absolutely nothing like the above, and has arrows pointing both to other modules and back from them (circular dependencies). This is common for a Rails application and is the trade off for being able to move so quickly initially.
Enforce the boundaries between those separate modules
Okay so there’s a massive problem with all of the approaches for modularisation, and it’s the main reason I say that Rails/Ruby aren’t set up for modularisation in the same way as a language like Java. The problem is that there’s no way to enforce the boundaries between the components you’ve now created.
What do I mean by enforcing boundaries?
Let’s quickly go back to the Java ‘module’:
a module must provide a module descriptor — metadata that specifies the module’s dependencies, the packages the module makes available to other modules, and more. (from this article)
This means that Module A cannot use the code from Module B, unless Module B explicitly makes that code available in a public interface and Module A explicitly lists it as a dependency. Beautiful. If you’re a developer working on that application you are forcibly prevented from creating circular dependencies (or any dependencies!) without explicitly defining them and it passing a PR review, and you’re forced to only use the public interface of a module so you can’t dive straight into its domain logic. Your application is now much less likely (but not impossible) to turn into a ball of mud with a dependency graph like a bowl of spaghetti because people are forced to think about and state their dependencies.
Why doesn’t Rails enforce boundaries?
There’s nothing that stops anyone from using code from anywhere else in a Rails application regardless of if it’s in the normal Rails folder structure, in a gem, in an engine or in a new folder structure outside of the app folder. The only difference is that in some instances you may need to require the file that the class you’re calling is in, or add it to the autoload config. In no situation do you need to list a dependency for a component and you’re never forced to use a public interface — you can delve straight into any class/module.
In fact, Rails actually makes it easier for you to unwittingly create these dependencies and spaghetti code because it uses Zeitwerk which auto-loads all files in the standard rails structure (and you can add additional paths to the autoload if you’d like, e.g. if you added a new folder outside of app/). This has benefits, namely speed and ease, in Zeitwerk’s own words:
You don’t need to write require calls for your own files, rather, you can streamline your programming knowing that your classes and modules are available everywhere
However those benefits come at the cost that after a while your code is less likely to have clear modules with public interfaces, enforced boundaries and clear dependencies.
Options for enforcing boundaries (tests and Packwerk)
There’s been different attempts at enforcing boundaries and here’s a couple of ways that people have had success with:
- Testing. There’s been some creative ways to use test suites to help enforce boundaries when using Rails engines. I’d really recommend reading the enforcing boundaries section of the modular monolith and Airtaskers section on enforcing boundaries for step by steps.
- Packwerk. Packwerk is a Ruby gem from Shopify that’s used to enforce boundaries and modularize Rails applications. It’s not the only linter of this type (check out flexport for using with Rails Engines) but it’s an incredibly lightweight tool that’s usable with any Rails code, not just engines. It’s being used at a massive scale at Shopify (they had 37 components and 48 packages in 2020, source) and other organisation including Simply Business are utilising it.
Packwerk allows you to create ‘packages’ (which can be any folder of any size, and packages can contain other packages inside them). A package has a public interface (which can be 1 or more files) and must explicitly define its own dependencies. Adding a simple command to your CI will check that the boundaries between your packages are enforced, raising a linting error if a violation occurs. You can allow a dependency between packages to occur, but similar to Java ‘modules’ you’re forced to explicitly define them which means that anybody looking at your application will be able to create a clear dependency graph and be confident when changing a package what other packages may be affected.
Lastly, if you’re looking to implement packwerk into an existing application and know that you’re going to have many violations, unlike the Rails engine and other approaches you’re not forced to re architect before implementing — they have a ‘stop the bleeding’ approach that allows you to only enforce the violations from the point you implement (similar to how you can ignore current rubocop errors when implementing a new cop so your build doesn’t suddenly have 5k errors to fix). Even better — when doing this, packwerk will automatically generate a list of the current violations to ignore — and that list can be used both to understand the current dependencies but also act as a starting point and future plan for how to reduce the dependencies of that package.
If you’re interested in trying Packwerk I’d recommend this video and their docs to get you started.
